基本概念
数据组装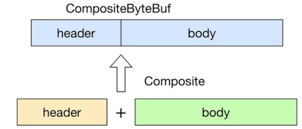
数据拆分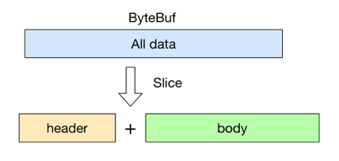
CompositeByteBuf主要用与用户进程中逻辑上拆分及组装ByteBuf,这样底层byte数组实际上是复用的,通过定义的读写索引来实现数据的读写,避免byte组的频繁创建,copy所带来的开销。
原理分析
组合
ByteBuf allByteBuf = Unpooled.wrappedBuffer(header, body);
组装拆分均为逻辑上的实现,如果header跟body均为数组的话,组装并不是创建一个新的byte[],然后将2个byte[]的数据copy到新的byte[]中,而是内部维护来一个List来存放这2个byte[]。
//Unpooled.java
/**
* @param maxNumComponents default value is 16
*/
public static ByteBuf wrappedBuffer(int maxNumComponents, byte[]... arrays) {
switch (arrays.length) {
case 0:
break;
case 1:
if (arrays[0].length != 0) {
return wrappedBuffer(arrays[0]);
}
break;
default:
// Get the list of the component, while guessing the byte order.
final List<ByteBuf> components = new ArrayList<ByteBuf>(arrays.length);
for (byte[] a: arrays) {
if (a == null) {
break;
}
if (a.length > 0) {
components.add(wrappedBuffer(a));
}
}
if (!components.isEmpty()) {
return new CompositeByteBuf(ALLOC, false, maxNumComponents, components);
}
}
return EMPTY_BUFFER;
}
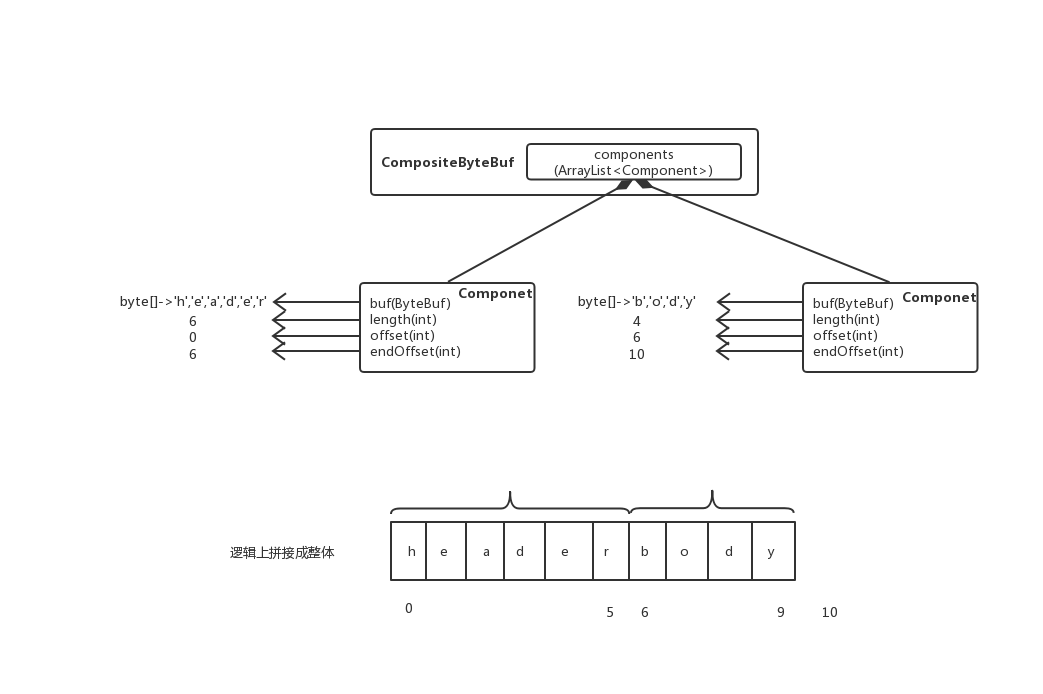
new CompositeByteBuf时会使用前面Unpooled.java类中构建的List<ByteBuf> components 创建Component对象
//CompositeByteBuf.java
private int addComponent0(int cIndex, ByteBuf buffer) {
checkComponentIndex(cIndex);
if (buffer == null) {
throw new NullPointerException("buffer");
}
int readableBytes = buffer.readableBytes();
// No need to consolidate - just add a component to the list.
Component c = new Component(buffer.order(ByteOrder.BIG_ENDIAN).slice());
if (cIndex == components.size()) {
components.add(c);
if (cIndex == 0) {
c.endOffset = readableBytes;
} else {
Component prev = components.get(cIndex - 1);
c.offset = prev.endOffset;
c.endOffset = c.offset + readableBytes;
}
} else {
components.add(cIndex, c);
if (readableBytes != 0) {
updateComponentOffsets(cIndex);
}
}
return cIndex;
}
Component对象通过内部的offset跟endOffset记录每个Component中的byte[]数据在整个CompositeByteBuf中的区间,
//Component.java
private static final class Component {
final ByteBuf buf;
final int length;
int offset;
int endOffset;
Component(ByteBuf buf) {
this.buf = buf;
length = buf.readableBytes();
}
void freeIfNecessary() {
// Unwrap so that we can free slices, too.
buf.release(); // We should not get a NPE here. If so, it must be a bug.
}
}
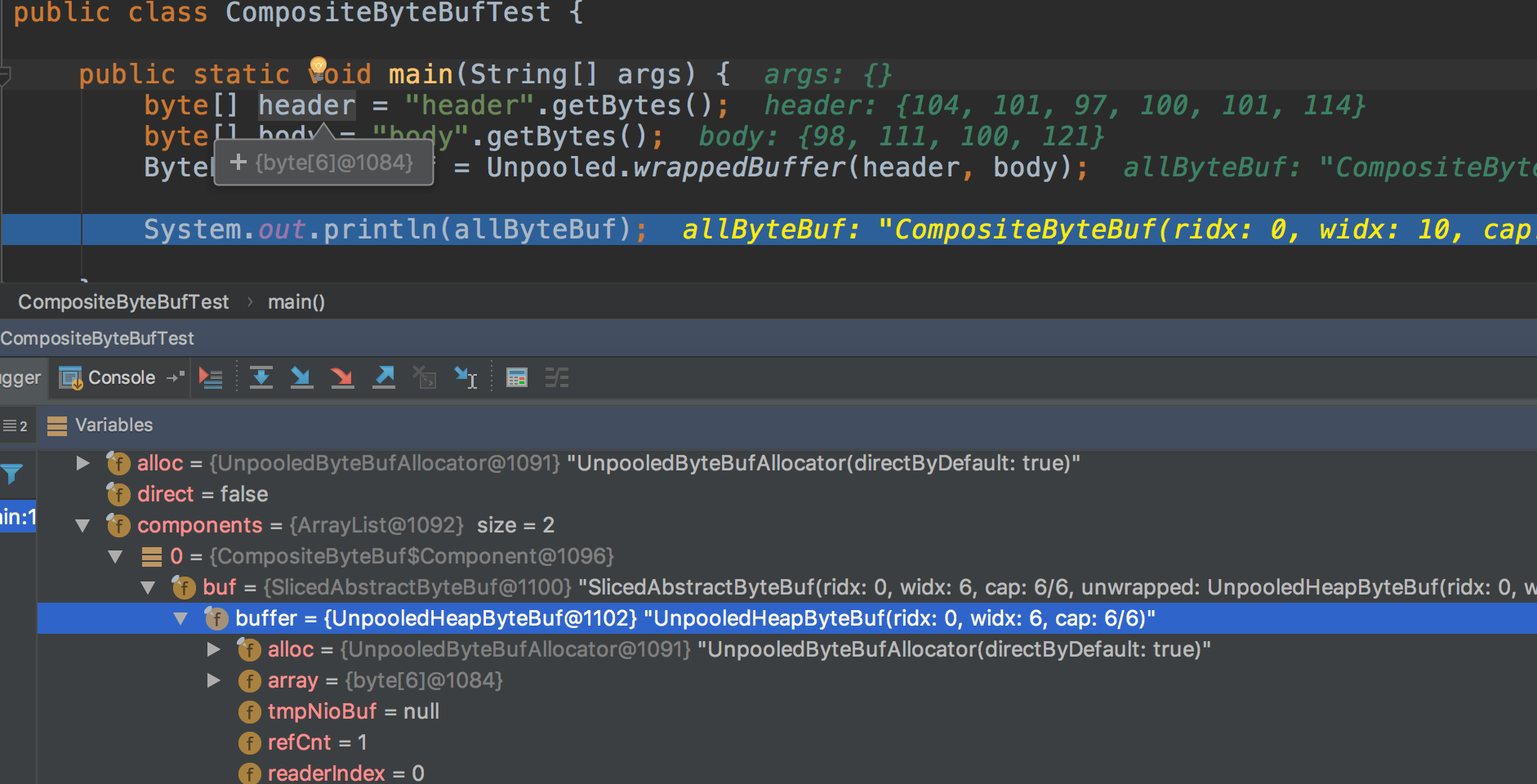
写个程序测试下,可以看到前面定义的byte数组header跟body子啊CompositeByteBuf类中是复用的,内部的ArrayList存放了header跟body对应的数组。
拆分
ByteBuf headerByteBuf = allByteBuf.slice(0, header.length);
ByteBuf bodyByteBuf = allByteBuf.slice(header.length, body.length);
slice方法会创建一个SlicedAbstractByteBuf对象,对应结构如下,其父类SlicedByteBuf用ByteBuf变量存放执行slice方法的对象,在这里对应是allByteBuf(CompositeByteBuf类)。前面提到的组合生成的CompositeByteBuf对象会被其slice方法生成的所有SlicedAbstractByteBuf共同引用。
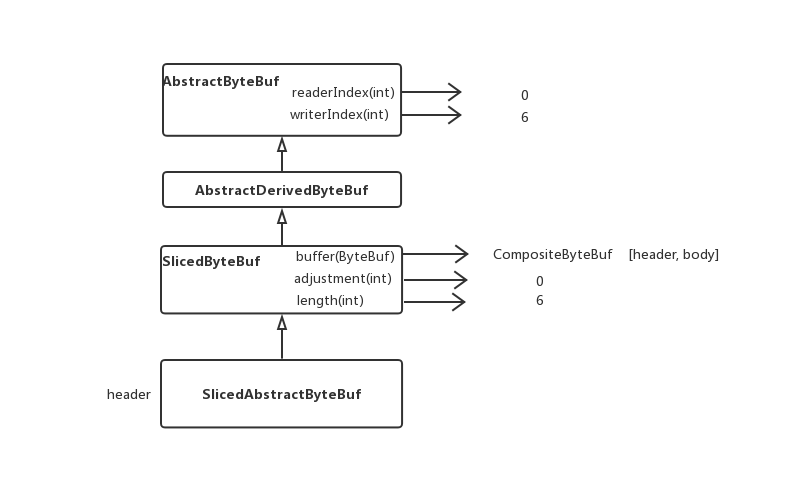
slice逻辑上拆分后的对象,会维护自己独有的读写索引等,然后通过索引值会帮我们做些边界check。
//test 1[正常] 正常读取SlicedAbstractByteBuf中的数据
ByteBuf headerByteBuf1 = allByteBuf.slice(0, header.length);
byte[] bytes1 = new byte[header.length];
headerByteBuf1.readBytes(bytes1);
System.out.println(new String(bytes1, StandardCharsets.UTF_8)); //header
//test 2[异常] 索引边界读数据check
ByteBuf headerByteBuf2 = allByteBuf.slice(0, header.length);
byte[] bytes2 = new byte[header.length + 1];
headerByteBuf2.readBytes(bytes2); //Exception in thread "main" java.lang.IndexOutOfBoundsException
//test 3[异常] 索引边界写数据check
ByteBuf headerByteBuf3 = allByteBuf.slice(0, header.length);
headerByteBuf3.writeChar('a'); //Exception in thread "main" java.lang.IndexOutOfBoundsException:
如果slice的拆分的部分包含header的全部以及body的前一部分,在读数据时,会遍历CompositeByteBuf里的components来copy对应的值。
总结
CompositeByteBuf复用了组合成分中的byte数组,避免了数据的反复拷贝
SlicedAbstractByteBuf复用了CompositeByteBuf对象(执行slice方法的对象),无论slice执行多少次,内部使用的数据都是一份CompositeByteBuf,读数据会基于CompositeByteBuf对象中的components数组,然后结合当前SlicedAbstractByteBuf对象的索引值来实现