按照官方文档翻译总结并实践
分片策略
cluster级别分片分配
分片配置
cluster.routing.allocation.enable
启用或禁用特定种类的分片的分配:
all- (默认)允许为各种分片分配分片。primaries- 仅允许分配主分片的分片。new_primaries- 仅允许为新索引的主分片分配分片。none- 任何索引都不允许任何类型的分片。
#临时配置
curl -X PUT 'http://localhost:9200/_cluster/settings' -d '{"transient":{"cluster.routing.allocation.enable" : "all"}}'
- 值设置成all,索引的主分片跟副本分片会均分到集群的各个node。
- 值设置成primaries,索引的主分片会均分到集群的各个node,副本分片处于unassigined状态。
- 值设置成new_primaries, 新增的索引的主分片会均分到集群的各个node,副本分片处于unassigined状态,之前创建的索引分片策略不受影响。
- 值设置成none时,新增的任何索引对应的分片会全部处于unassigined状态。
分片重新均衡分配
cluster.routing.rebalance.enable
为特定类型的分片启用或禁用重新平衡:
all- (默认)允许各种分片的分片平衡。primaries- 仅允许主分片的分片平衡。replicas- 仅允许对副本分片进行分片平衡。none- 任何指数都不允许任何类型的碎片平衡。
该参数主要含义是,当我们在cluster中新增node时,新增加的node是否均衡索引的分片。比如10个分片,5主5备,当前集群2个节点已经均分了,当新增加第三个节点时,如
cluster.routing.rebalance.enable设置的是node,那么新增的节点不会被分配到分片。
cluster.routing.allocation.allow_rebalance
指定何时允许分片重新平衡:
always- 始终允许重新平衡。indices_primaries_active- 仅在群集中的所有主分片分配完成后。indices_all_active- (默认)仅当分配了群集中的所有分片(主和副本)分配完成后。
默认值是
indices_all_active,意味着需要等到所有的分片均处于可用状态时,才会进行重新平衡分配操作,可以减少集群初始启动时机器之间的交互。
TIPS:为了避免机器重启导致频繁的再平衡分配操作,可以设置推迟分片分配的时间。
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
简化式分片均衡分配
以下设置一起用于确定每个分片的放置位置。当没有允许的重新平衡操作可以使任何节点的权重更接近任何其他节点的权重时,群集是平衡的balance.threshold。
cluster.routing.allocation.balance.shard定义节点(float)上分配的分片总数的权重因子。默认为
0.45f。提高这一点会增加均衡群集中所有节点的分片数量的趋势。cluster.routing.allocation.balance.index定义在特定节点(float)上分配的每个索引的分片数量的权重因子。默认为
0.55f。提高这一点会增加在集群中所有节点上均衡每个索引的分片数的趋势。cluster.routing.allocation.balance.threshold应执行的操作的最小优化值(非负浮点数)。默认为
1.0f。提高此选项将导致群集在优化分片平衡方面不那么积极。
需要注意的是:
无论平衡算法如何配置,如果配置了强制感知或分配过滤,可能平衡分配将不被允许重新平衡。
基于磁盘的分片分配策略
在确定是将新分片分配给该节点还是主动从该节点重新将分片分配出去之前,Elasticsearch会考虑节点的可用此盘空间。
以下是可以在elasticsearch.yml配置文件中配置的设置,或使用cluster-update-settings API 在活动群集上动态 更新的设置:
cluster.routing.allocation.disk.threshold_enabled默认为
true。设置为false禁用磁盘分配决定器。cluster.routing.allocation.disk.watermark.low控制磁盘使用的低水位线。默认为
85%,意味着Elasticsearch不会将分片分配给使用磁盘超过85%的节点。它也可以设置为绝对字节值(如500mb),以防止Elasticsearch在小于指定的可用空间量时分配分片。此设置不会影响新创建的索引的主分片,或者特别是之前从未分配过的任何分片。cluster.routing.allocation.disk.watermark.high控制高水印。它默认为
90%,意味着Elasticsearch将尝试从磁盘使用率超过90%的节点重新定位分片。它也可以设置为绝对字节值(类似于低水印),以便在节点小于指定的可用空间量时将其从节点重新定位。此设置会影响所有分片的分配,无论先前是否分配。cluster.routing.allocation.disk.watermark.flood_stage控制磁盘的最大容量,它默认为95%,当节点磁盘容量到达95%时,索引会被置为只读模式,不允许继续写数据。这是防止节点耗尽磁盘空间的最后手段,可用在释放完磁盘空间后,通过下面指令解除read-only模式:
PUT _settings { "index.blocks.read_only_allow_delete": "false" }
不能在这些设置中混合使用百分比值和字节值。要么全部都设置为百分比值,要么全部都设置为字节值。这样我们就可以验证设置是否内部一致(即,低磁盘阈值不超过高磁盘阈值,并且高磁盘阈值不超过泛洪阶段阈值)。
cluster.info.update.interval
Elasticsearch应该多久检查一次集群中每个节点的磁盘使用情况。默认为30s。
cluster.routing.allocation.disk.include_relocations
默认为true,这意味着Elasticsearch将在计算节点的磁盘使用情况时考虑当前正在重定位到目标节点的分片。但是,将重新定位分片的大小考虑在内可能意味着节点的磁盘使用量偏差估计偏高,因为重定位可能完成90%,最近检索的磁盘使用量将包括重定位分片的总大小以及正在运行的重定位已经使用的空间。
分片感知分配
在同一物理服务器,多个机架或多个区域或域中的多个VM上运行节点时,同一物理服务器上,同一机架中或同一区域或域中的两个节点更可能会同时崩溃,而不是两个不相关的节点同时崩溃。
如果Elasticsearch 能了解硬件的物理配置,则可以确保主分片及其副本分片分布在不同的物理服务器,机架或区域中,以最大程度地降低同时丢失所有分片副本的风险。值得高兴的是我们可以通过分片识别设置告诉Elasticsearch对应的硬件配置。
如何使用
在elasticsearch.yml配置文件中可用给各个节点配置属性值(可以配置多个,前缀叫node),例如配置2个属性,一个rack_id,一个zone_id,属性名称可用任意取。(跟自带的一些配置名称不一样应该都可以,就是不要叫node.name这种)我们这里用rack_id表示机架,zone_id表示机房。
node.rack_id: r1
node.zone_id: z1
依次起3个节点,2个为r1,一个为r2。
node.name: node1 -> node.rack_id: r1
node.name: node2 -> node.rack_id: r1
node.name: node3 -> node.rack_id: r2
通过配置:cluster.routing.allocation.awareness.attributes: rack_id来根据rack_id去分片分配感知。
配置前,所有分片均分在各个节点。
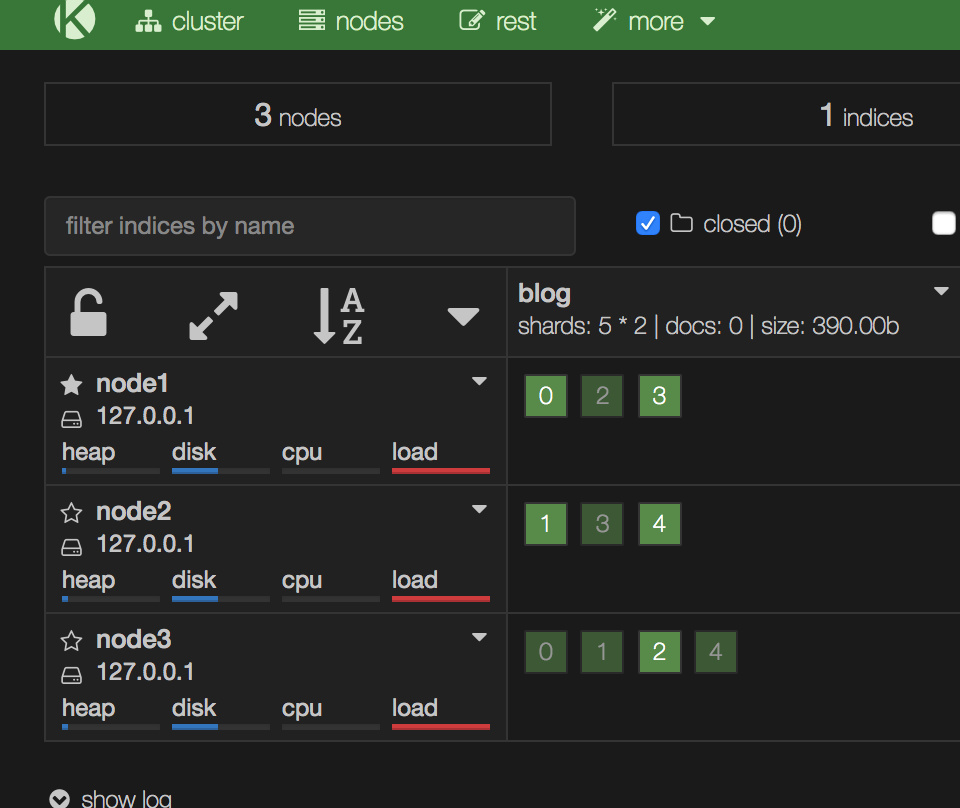
这种配置就存在前面说的问题,node1跟node2可以看成一个机架上的2个实例(单机架2台机器上的2个ES实例,后者单机架单机器上2个ES实例),如果机架断电了,索引中分片3上面的数据就丢了,访问不了。
当配置cluster.routing.allocation.awareness.attributes: rack_id后,配置方式如下:
curl -X PUT 'http://localhost:9200/_cluster/settings' -d '{"transient":{"cluster.routing.allocation.awareness.attributes" : "rack_id"}}'
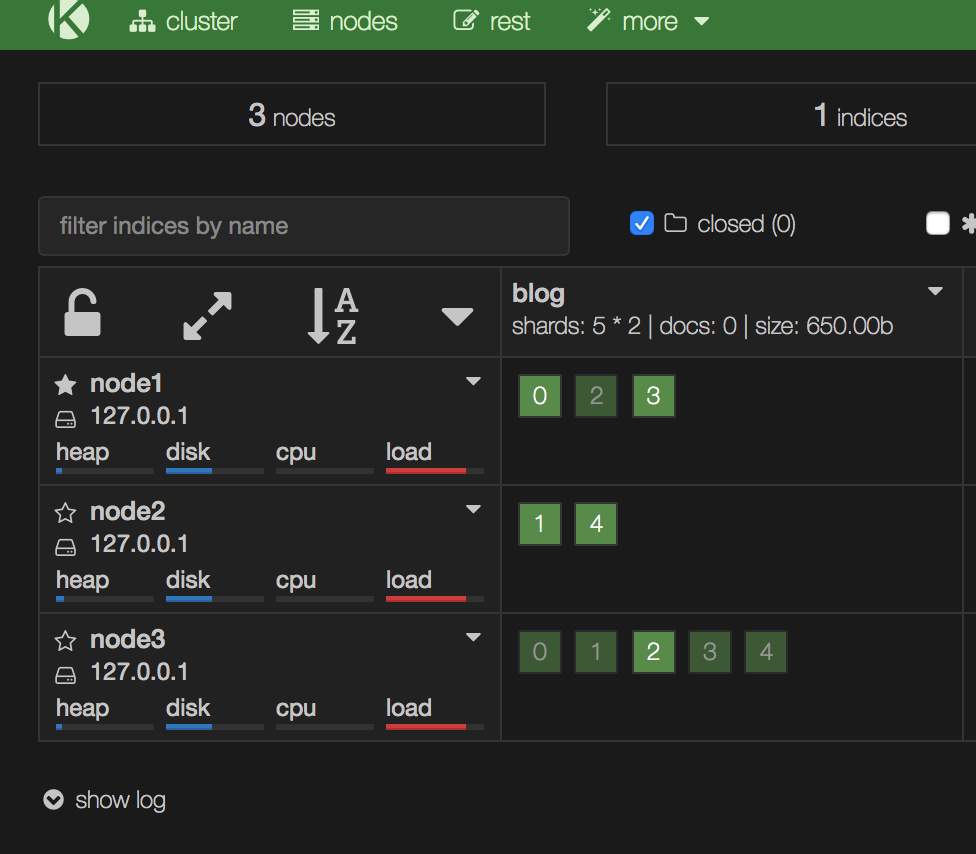
node3的rack_id值为r2,node1跟node2都是r1,所以最终实现了主副本分片未落到一个r1中。
强制感知分配
上面的分片感知又可以称为普通感知,普通感知存在一个问题,就是如果存在4个节点n1,n2,n3,n4,配置对应的rack_id属性如下:
node.name: node1 -> node.rack_id: r1
node.name: node2 -> node.rack_id: r1
node.name: node3 -> node.rack_id: r2
node.name: node4 -> node.rack_id: r2
如果未配置强制感知,则当r2下面的node3,node4挂了以后,原先分给node3,node4的分片会重新再node1跟node2上分配。
按照rack_id做普通感知
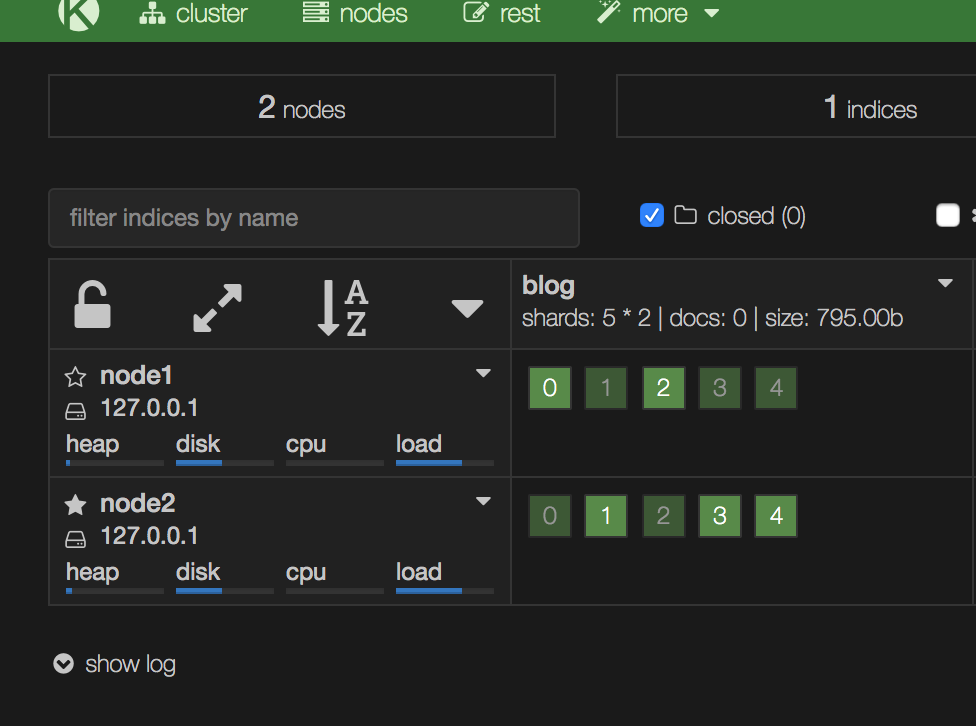
4个节点正常情况下:
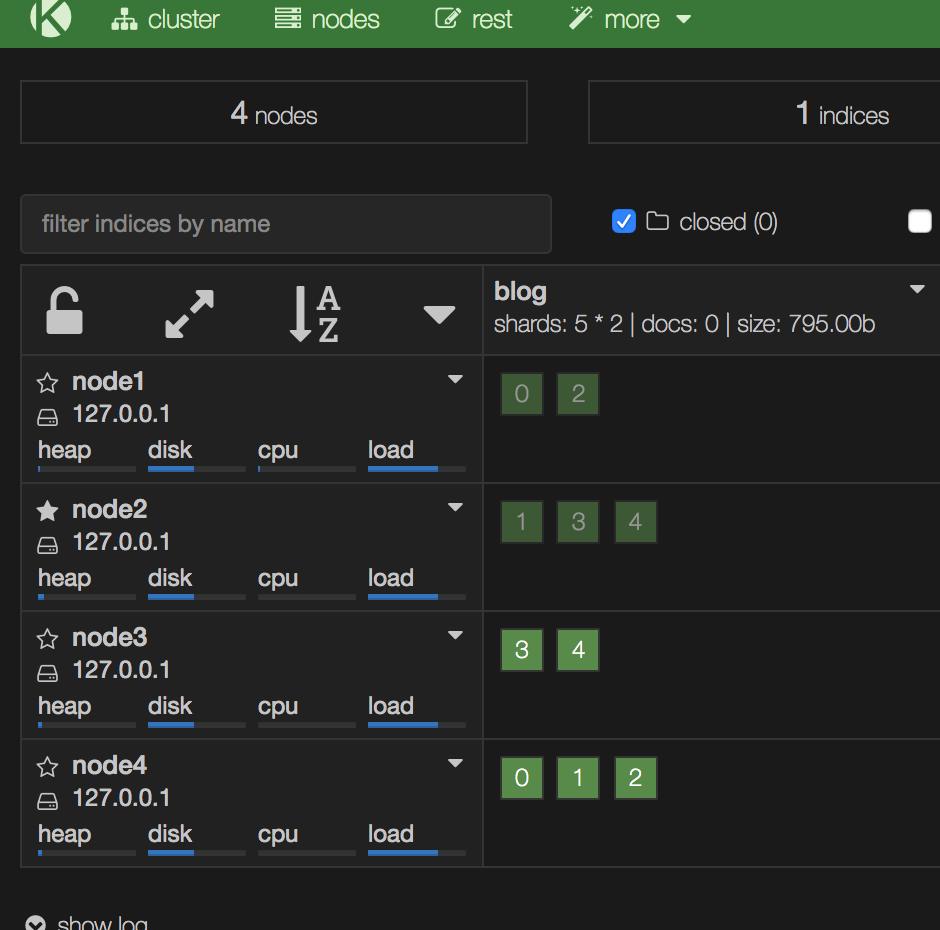
node3,node4挂了情况下
过一段时间会重新分配,这样所有的分片均落在rack_id为r1下面了:
按照rack_id做强制感知
在节点配置文件中再增加参数:
cluster.routing.allocation.awareness.force.rack_id.values: r1, r2
之前的cluster.routing.allocation.awareness.attributes: rack_id配置也需要保留
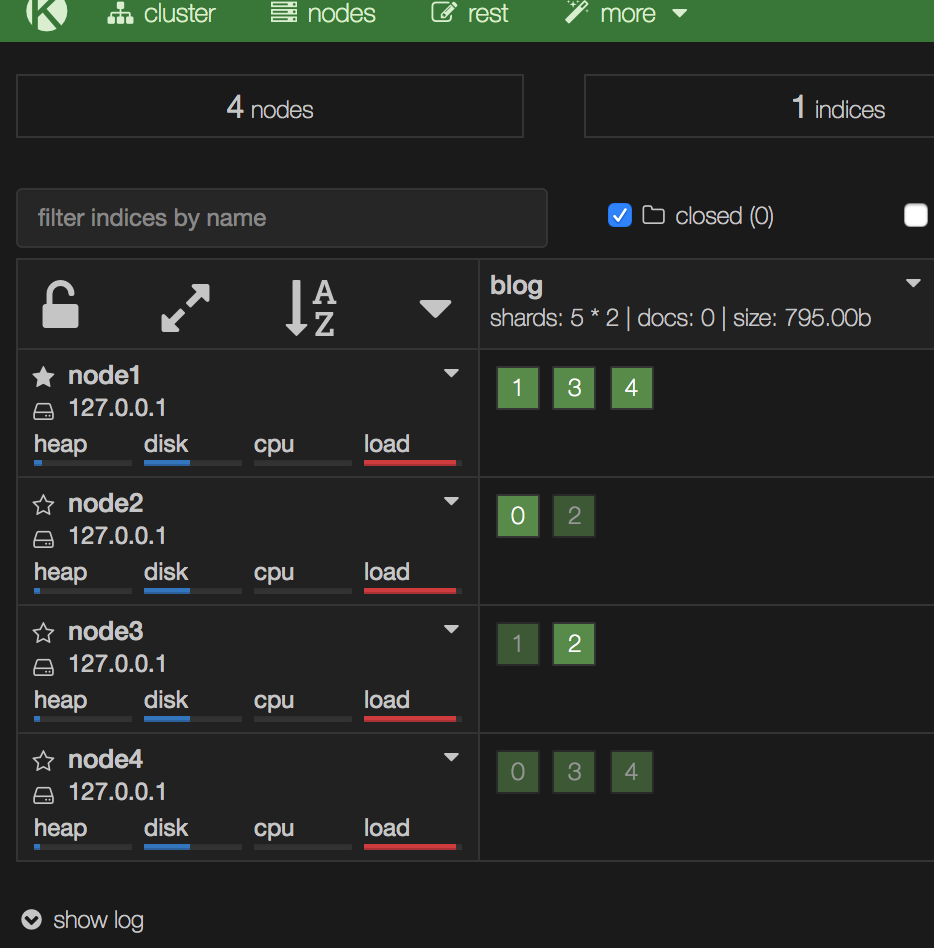
4个节点均正常
node3,node4挂了
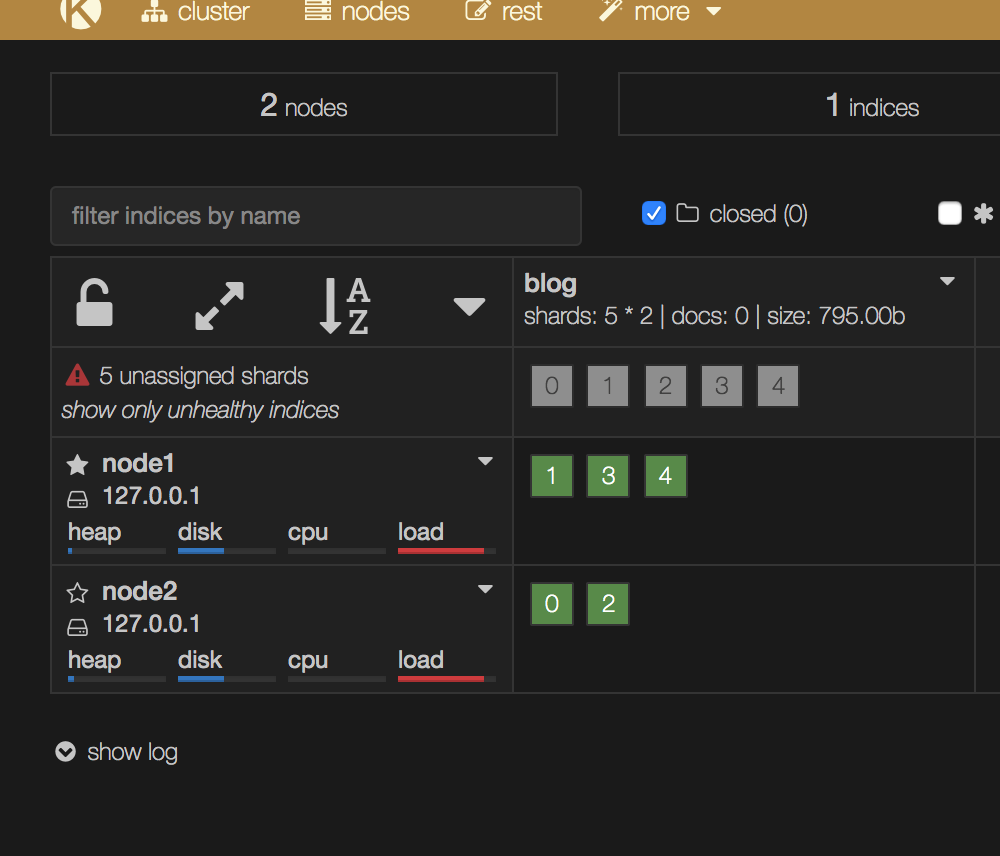
可以看到有5个副本分片始终处于unassigned状态了。
过滤器分配
不同于索引分片分配提供了针对每个索引设置来控制分片到节点的分配,群集级分片分配过滤允许您允许或禁止从任何索引到特定节点的分片分配。
可用的动态集群设置如下,其中{attribute} 引用任意节点属性:
cluster.routing.allocation.include.{attribute}将分片分配给
{attribute}至少具有一个逗号分隔值的节点。cluster.routing.allocation.require.{attribute}仅将分片分配给
{attribute}具有所有逗号分隔值的节点。cluster.routing.allocation.exclude.{attribute}不要将分片分配给
{attribute}具有任何逗号分隔值的节点。
还支持这些特殊属性:
_name |
按节点名称匹配节点 |
|---|---|
_ip |
按IP地址匹配节点(与主机名关联的IP地址) |
_host |
按主机名匹配节点 |
群集范围的分片分配过滤的典型用例是,当您想要停用某个节点时,您希望在关闭之前将分片从该节点移动到群集中的其他节点。
例如,我们可以使用其IP地址解除节点,如下所示:
PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
只有在不破坏其他路由约束的情况下才能重新定位碎片,例如永远不会将主碎片和副本碎片分配给同一节点。
除了将多个值列为逗号分隔列表之外,还可以使用通配符指定所有属性值,例如:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "192.168.2.*"
}
}
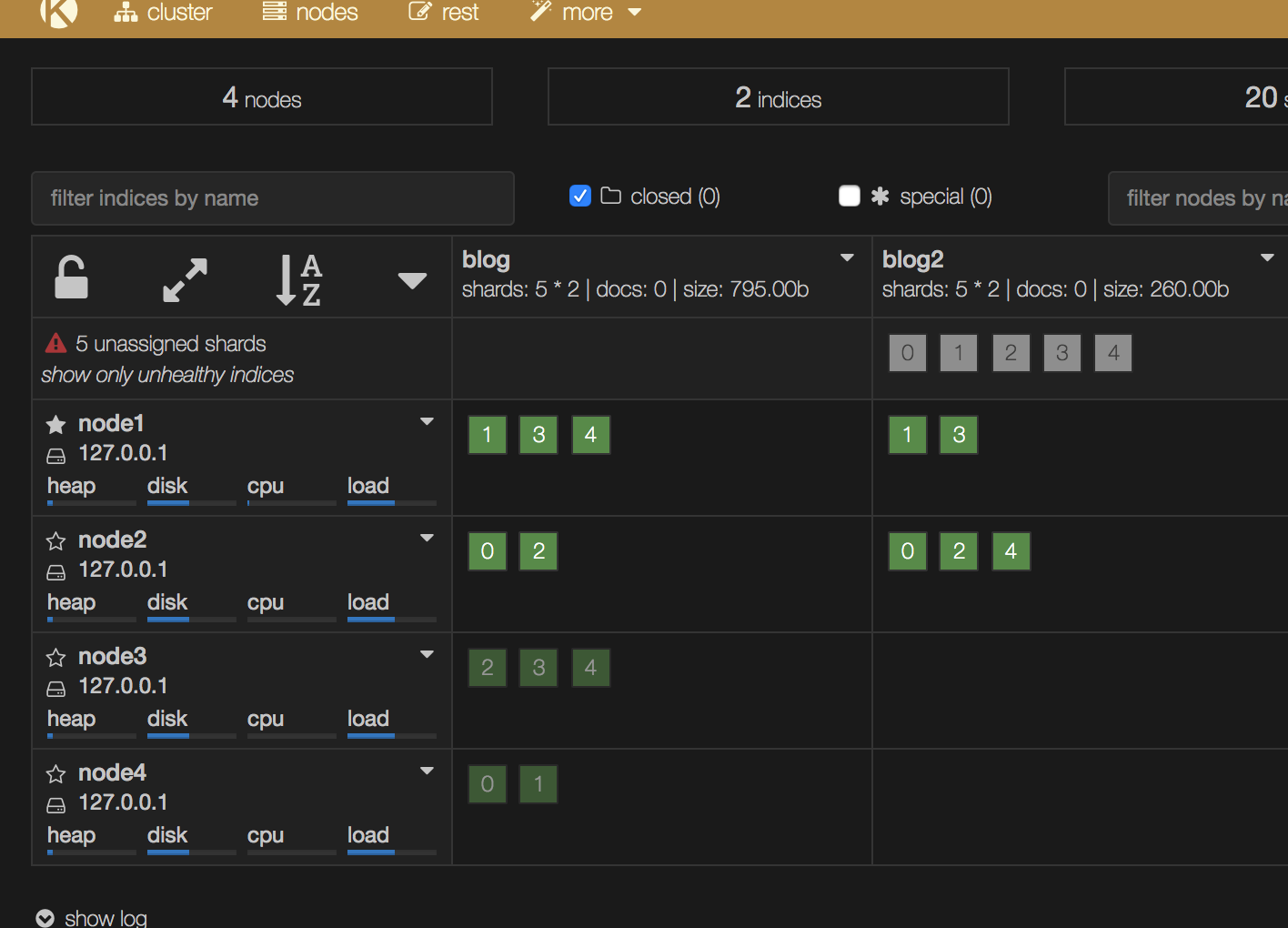
{attribute}属性是跟感知分配中讲的rack_id是一类,都是可以自定义命名的,如果我们配置索引分片只分配给r1属性的节点,只需要改下集群配置。
curl -X PUT "http://localhost:9200/_cluster/settings" -d'
{
"transient" : {
"cluster.routing.allocation.include.rack_id" : "r1"
}
}
配置只作用于新增的index,旧的不受影响,可以看到新增的blog2有5个副本一直处于未分配状态,这是因为只能将分片分配在r1,集群又针对rack_id做强制感知的结果。